
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- pythonForEverybody
- 파이썬
- 선형대수
- deep learning
- mlops
- 벡터 간 유사도
- skip-gram
- convolution
- Long Short Term Memory
- object detaction
- 시소러스
- 차원 감소
- Linear algebra
- py4e
- f1-score
- CBOW
- Multi-Layer Perceptron
- Gated Recurrent Unit
- 상호 정보량
- nn.Module
- 1x1 Convolution
- 분포 가설
- dl
- excel
- pytorch
- Charlse Severance
- GoogLeNet
- docker
- Python
- 동시발생 행렬
- Today
- Total
Tech & TIL
BERT 논문 리뷰 본문
Transformer 다음에 나온 논문으로, NLP 분야에서 꼭 알아야 하는 BERT 논문을 리뷰해보자.
Table of contents
- 개요
- 이전 연구와의 차이점
- 메인
- 결론
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
1. 개요
BERT
- 트랜스포머 기반 양방향 인코더 표현
주요 특징
- Pre-training
- Unlabeled Data
- Bidirectional
- MLM(Masked Language Modeling)
- NSP(Next Sentence Prediction)
효과적인 분야
- QA (Question Answering)
- Language Inference
2. 이전 연구와의 차이점

3. BERT 주요 특징
Pre-training & Fine-tuning
BERT를 사용하는 것은 2가지 단계를 따른다.
1. Pre-Training
2. Fine-Tuning
BERT의 가장 큰 장점 중 하나가 바로 위 내용이다. 대규모 말뭉치로 train 시켜놓으면 다양한 Task에 fine-tuning을 해서 사용할 수 있다.
BERT를 pre-train할 때 사용되는 2가지 기법은 아래와 같다.
MLM
BERT에서는 input sequence에 15%를 [Mask]를 씌우는 특징이 있다. 예컨대, "어제 카페 갔었는데 사람 많더라"라는 문장이 있을 때, "어제 카페 갔었는데 [Mask] 많더라"로 마스킹되어서 들어간다. 이를 예측하는 과정을 통해 BERT가 학습된다.
NSP
Next Sentence Prediction, 두 개의 문장이 입력으로 들어오면 뒤 쪽에 오는 문장이 실제로 이어지는 문장인지 예측하는 과정도 BERT 학습과정 중 일부이다. 예컨대, "어제 카페에 갔다. 그 카페에는 사람이 많았다."라는 문장이 들어왔을 때는 'True'로 예측해야 하고, "어제 카페에 갔다. 동물원에는 사람이 많았다."가 들어오면 'False'로 예측하는 것이다.
Special Token
BERT에서는 tokenization을 할 때 2개의 special token이 들어간다. [CLS]와 [SEP] 토큰이다. CLS 토큰은 classification token으로 전체 시퀀스를 분류하는 의미를 지니게 된다. SEP 토큰은 seperate 토큰으로 두 개의 시퀀스를 나눠주는 역할을 한다. 문장이 끝날 때 하나씩 온다.
Embedding Layer
BERT는 Embedding Layer에서도 차이를 보여주는데, Transformer에서 Position Embedding만 사용하던 방식에서 몇 가지가 더 추가된 모습을 띤다. 구조는 아래와 같다.
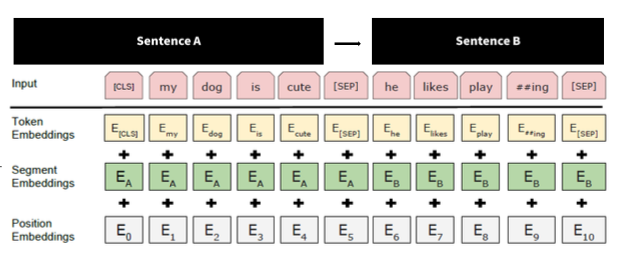
- Token Embeddings: tokenized된 sequence A & B가 입력으로 들어오면 input token들을 임베딩 시켜준다.
- Segment Embeddings: position embedding을 보면 숫자가 0-10까지 들어가는데 이것으로는 두 개의 문장이 어디서부터 어디까지인지 알 수 없다. 따라서 AAAA와 BBBB처럼 두 개의 문장을 구별하는 역할을 한다.
- Position Embeddings: position embedding이 없다면 어느 단어가 앞이고 어느 단어가 뒤인지 transformer 구조에서는 알 수가 없기 때문에 위치 정보를 주기 위해 넣는다.
Pre-train에 사용된 데이터 : BooksCorpus + Wikipedia
4. 정리
BERT는 Transformer의 구조를 거의 동일하게 사용하고 있지만, Transformer에서 Decoder 부분을 제거하고 Encoder 부분만 사용하는 특징이 있다. Transformer처럼 인코더-디코더 구조를 사용해서 input이 있을 때 특정한 output을 만들어내는 task를 하는 모델이라기보다는 대규모 말뭉치 학습을 통해 단어의 분산 표현을 보다 잘 담을 수 있는 모델이라고 생각하는 것이 좋을 것 같다. 잘 학습된 단어 분산 표현을 통해 여러 가지 새로운 task에 맞게 fine-tuning 해서 사용할 수 있는 특징이 있기 때문에 각종 competition에서 유용하게 사용되고 있다.
'NLP' 카테고리의 다른 글
| [NLP] Word2Vec (0) | 2021.09.23 |
|---|---|
| [NLP] 단어의 의미를 학습시키는 방법 (0) | 2021.09.16 |
| [NLP] 자연어처리란? (0) | 2021.09.16 |

